Today, let's talk about some history. Not that World War history, but the history and evolution of C# as a language. I would like to analyze the principal parts in one of the mainstream languages of mass production in today's software. Beware that most of what i am about to say is the fruit of much research, in part because when C# and the .NET became available i had not written a single line of code yet, so you can say that i am a newborn in this world.
I'm inclined to change that, though, but every new discovery is done with much enthusiasm on my part, and i'm very proactive, which sometimes may upset my colleagues. One of the reasons i'm writing this article - and this blog all the same - is because i love to learn new things and share it with others. Enough talk, let's get to the point!
The beginning of .Net
The .NET platform brings a brand new and fresh way of programming your applications. Microsoft created the term "Managed Code" to refer to code that runs on their runtime virtual machine called CLR (Common Language Runtime). The CLR is responsible for managing low level stuff that your C# (or VB, or other .NET language) emits in the form of IL (Intermediate Language). This scheme brought from Wikipedia shows how this works.

I'm inclined to change that, though, but every new discovery is done with much enthusiasm on my part, and i'm very proactive, which sometimes may upset my colleagues. One of the reasons i'm writing this article - and this blog all the same - is because i love to learn new things and share it with others. Enough talk, let's get to the point!
The beginning of .Net
The .NET platform brings a brand new and fresh way of programming your applications. Microsoft created the term "Managed Code" to refer to code that runs on their runtime virtual machine called CLR (Common Language Runtime). The CLR is responsible for managing low level stuff that your C# (or VB, or other .NET language) emits in the form of IL (Intermediate Language). This scheme brought from Wikipedia shows how this works.
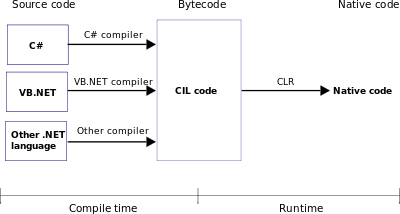
Basically, the code that you write is compiled to IL by the C# compiler and then, when you run the program, the JIT Compiler translates that IL into native code. This seems to happen at runtime and has it's cost, as Eric Lippert notes in this article.
This is all too cute, but what does managed code actually bring us?
IL
For a start, the IL language is an advantage all by itself. If we think about it, compiling to a common language means that a new language can be added to the .NET family more easily. IL represents an abstraction in the sense that all you have to do is make sure your language compilers emit the correct IL. Of course this is a very generic and broad definition, but Microsoft has proven this true by creating a numerous family of programming languages for .NET.
For a comprehensive list of CLI languages refer to this article. The number and nature of all those languages (since OO languages to Functional) prove how versatile the CLR really is.
Security
I think that in this aspect, the most important thing to note is that, being a platform in itself, the CLR knows what it is running. The CLR has security mechanisms to ensure that the code is safe and acts as a supervisor on it. It collects metadata associated with assemblies loaded called Evidence. Evidence contains information about the assembly such as the Publisher, the Application Directory, etc. This is analyzed and access is given to the code. This is a very shallow explanation as i don't know any boring details, but you can see them here.
Base Class Library
This is where it gets interesting. The BCL represents all those basic classes and structs that are the foundation of the .NET Framework. I say .NET because the BCL is shared between the .NET family. This means that the same classes, methods, etc available in C# are also available in VB.NET. The main objective of this approach is to make our job easier as programmers and provide consistency inside the platform. There, we can find a unified approach to do low level stuff such as writing to streams, interacting with the OS and all the base classes and support for many features of the entire .NET Framework. It is also ECMA standardized and available for other implementations of it such as Mono.
Garbage Collection
This is another feature that i never lived without, hence i don't know what to say when you ask me what the world was before it. But i will try. When we create an object, that object lives on the memory of our computer. That object is now in scope (reachable by user code) and while it stays that way, the GC (Garbage Collector) will not mark it for collection.
I can only imagine in older days how life was, when there was no GC. Taking care of memory is a difficult thing, i can imagine. Imagine you have to care with every little variable, every little piece of code, caring to tell the system that you're done with that object and that it's memory can be reused. I bet it was a dreadful thing and also very, very error prone. I can also bet that many applications suffered from memory leaks without knowing it, only to fail miserably at some point in time.
So, one of the tools the GC uses to clear your memory is the concept of scope. Scope tells it that that object is not accessible to user code anymore and can safely be marked for collection. Don't think that GC collection is triggered by a variable going out of scope, it doesn't. In reality, the GC has it's own method, and it is not really possible to determine when a collection will be triggered. The reasons are many: it can be because the memory is under pressure, because Generation 0 has run out of space...
Regarding Generations, when the GC runs, it starts at strategic root objects and recursively marks each object's references as reachable. When an object is not reachable, it is marked for collection and it's Finalize method is called. After that, the memory is freed, but the objects that were not finalized are promoted to the next Generation. We have Generation 0, 1 and 2. The Generation 2 is where the long lived objects exist and those are not very likely to disappear. We are talking about static objects, globals and so on.
So, GC is really there to make our life easy, so we must be grateful that it exists. I don't have to care with freeing memory, only my business logic. But of course, every one of us has to care with making life easier for the GC and clear all those not needed references. That's a far easier job and one i prefer to perform. To end this subject, i want to note that this was a very, very shallow introduction and that you can read more about GC stuff here.
Safety
When i talk about safety here is basically telling you that you are safe from all that low level stuff that you get in C, like pointers, raw access to memory... When you create an object in the heap, you get an abstract reference to that object in memory and never an address of that block. Exceptions are another kind of safety you get from managed code. When an exception occurs, you can react to it as well as have all the information about it right there in the IDE. On unmanaged code it is a little more tricky and sometimes the program may break without warning.
Productivity
Of course, i couldn't end the article without talking about this. This is probably one of the most important side-effects of the introduction of the .NET Framework. The languages based on .NET are very productive, easy to learn, programmer-friendly and, of course, backed by a ton of libraries that give life to the .NET world. Throughout the years, it has become mainstream and we watched a boom in the methodologies, tools and productivity helpers that many companies and individuals are making. The technology has evolved even more now, and today it has become one of the main platforms for new applications. In C#, for example, we have now Generics, Linq, Lambdas, async programming and more to come. But soon enough i will talk about those evolutions.
Along with this, we have one of the most powerful, extensible and versatile IDE's in the world. Of course i'm talking about Visual Studio. Although one is independent from the other, and many use other IDE's, i couldn't leave this apart from the .NET evolution. As the platform evolved, so has the tool and it's support for the features and leverage of the framework power.
Disadvantages
Managed code brought some disadvantages with it, as many smart people denoted. Speed is one of the most notorious. Of course, having a language compiled directly to machine code is much more efficient than having a virtual machine compiling IL to machine code. This is a significant factor to look for when developing low level systems such as OS's and low level drivers. For the most of the applications, it really is irrelevant, because after all if the end user doesn't ever perceive the difference, then there is virtually no difference.
Another disadvantage is that multiplatform is not supported out-of-the-box by Microsoft, but there are multiplatform implementations of the .NET framework, such as Mono.
In the next chapters we're going to look at real code and the evolution that was performed from C# 1.0 to C# 2.0. I don't know if i will cover it all in one post, because i want to show with great detail some of the changes, but let's see!
Thanks to all for reading!
Comments
Post a Comment